Topic Modeling of Product Reviews on Amazon Scraped using Selenium in Python
A tutorial demonstrating scraping product reviews from Amazon and extracting and analysing the topics from the text data.


The blog covers the step-by-step process to scrap product reviews from Amazon webpage and analysing main topics from the extracted data. We will scrap 1000 reviews from the Amazon for Apple iPhone 11 64GB. With this data, we will convert each review doc into bag-of words for applying the topic modeling algorithm. We will be using Latent Dirichlet Allocation (LDA) algorithm in this tutorial. The main python libraries used are:
- selenium: Selenium is a portable framework for testing web applications. We will be using this to interact with the browser and open URLs (https://pypi.org/project/selenium/)
- gensim: Gensim is an open-source library for unsupervised topic modeling and natural language processing, using modern statistical machine learning (https://pypi.org/project/gensim/)
Web scraping is a technique for extracting information from the internet automatically using a software that simulates human web surfing. Web scraping helps us extract large volumes of data about customers, products, people, stock markets, etc. It is usually difficult to get this kind of information on a large scale using traditional data collection methods. We can utilize the data collected from a website such as e-commerce portal, social media channels to understand customer behaviors and sentiments, buying patterns, and brand attribute associations which are critical insights for any business.
The first and foremost thing while scraping a website is to understand the structure of the website. We will be scraping the reviews for Apple iPhone 11 64GB on Amazon.in website. We will scrape 1000 reviews from different users across multiple pages. We will scrape user name, date of review and review and export it into a .csv file for any further analysis.
- Instll selenium package (if not already worked with before) using command '!pip install selenium'
- Import webdriver from selenium in the notebook which we use to open an instance of Chrome browser
- The executable file for launching Chrome 'chromedriver.exe' should be in the same folder as the notebook
#Importing packages
from selenium import webdriver
import pandas as pd
The below code opens the new chrome browser window and open our website with the url link provided. By the way, chrome knows that you are accessing it through an automated software!
driver = webdriver.Chrome('chromedriver.exe')
url = 'https://www.amazon.in/Apple-iPhone-11-64GB-White/product-reviews/B07XVMCLP7/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews&pageNumber1'
driver.get(url)
Woha! We just opened an url from python notebook.
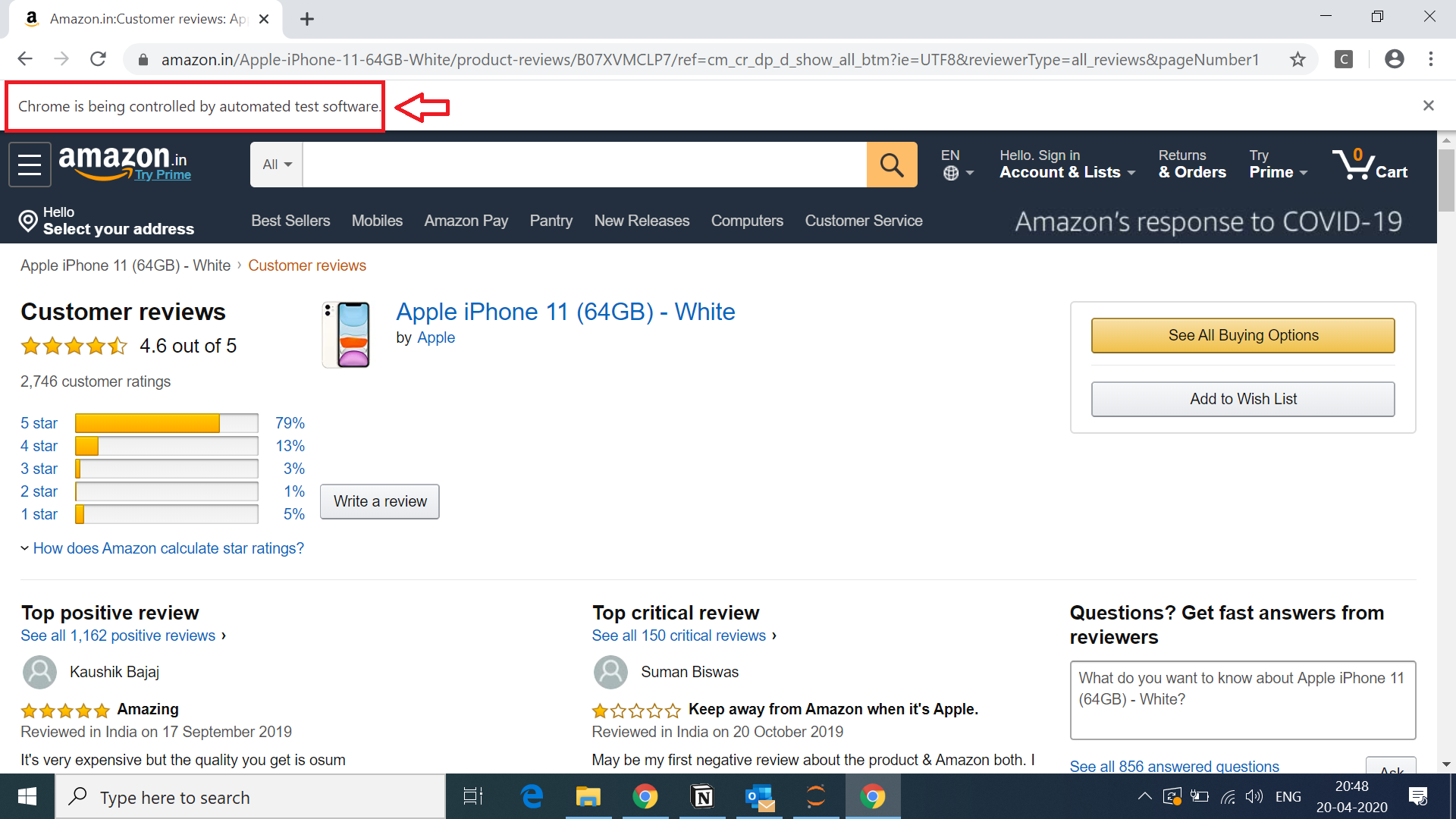
We will inspect 3 items (user id, date and comment) on our web page and understand how we can extract them.
-
Xpath for User id: Inspecting the userid, we can see the highlighted text represents the XML code for user id.The XML path (XPath)for the userid is shown below:
//*[@id="customer_review-RBOIMRTKIYBBR"]/div[1]/a/div[2]/span
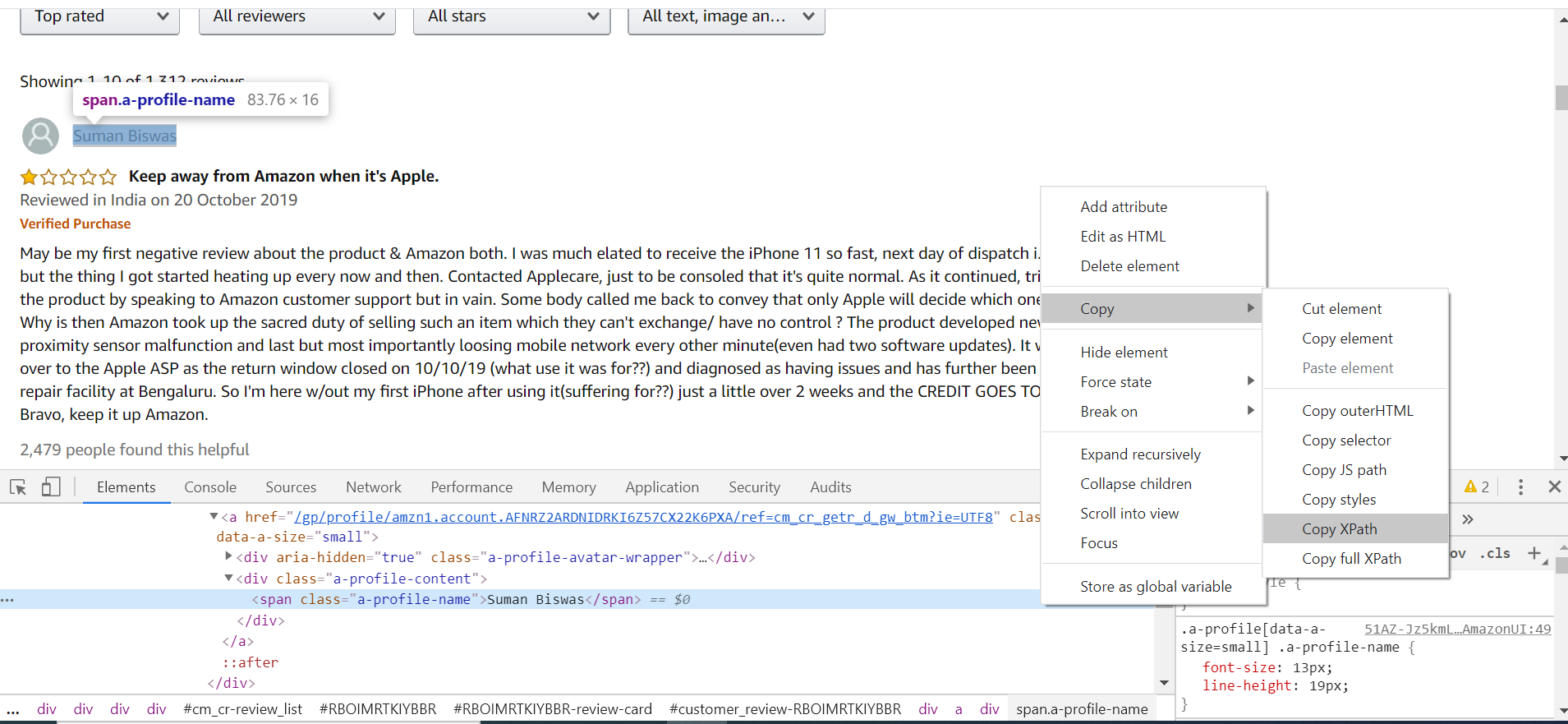
There is an interesting thing to note here that the XML path contains a review id, which uniquely denotes each review on the website. This will be very helpful as we try to recursively scrape multiple comments.
- Xpath for Date & review: Similarily, we will find the XPaths for date and review.
- Selenium has a function called “find_elements_by_xpath”. We will pass our XPath into this function and get a selenium element. Once we have the element, we can extract the text inside our XPath using the ‘text’ function.
- We will recursively run the code for different review id and extract user id, date and review for each review id. Also, we will recursively go to next pages by simply changing the page numbers in the url to extract more comments until we get the desired number of comments.
driver = webdriver.Chrome('chromedriver.exe')
#Creating empty data frame to store user_id, dates and comments from ~5K users.
data = pd.DataFrame(columns = ['date','username','review'])
j = 1
while (j<=130):
# Running while loop only till we get 1K reviews
if (len(data)<1000):
url = 'https://www.amazon.in/Apple-iPhone-11-64GB-White/product-reviews/B07XVMCLP7/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews&pageNumber=' + str(j)
driver.get(url)
ids = driver.find_elements_by_xpath("//*[contains(@id,'customer_review-')]")
review_ids = []
for i in ids:
review_ids.append(i.get_attribute('id'))
for x in review_ids:
#Extract dates from for each user on a page
date_element = driver.find_elements_by_xpath('//*[@id="' + x +'"]/span')[0]
date = date_element.text
#Extract user ids from each user on a page
username_element = driver.find_elements_by_xpath('//*[@id="' + x +'"]/div[1]/a/div[2]/span')[0]
username = username_element.text
#Extract Message for each user on a page
review_element = driver.find_elements_by_xpath('//*[@id="' + x +'"]/div[4]')[0]
review = review_element.text
#Adding date, userid and comment for each user in a dataframe
data.loc[len(data)] = [date,username,review]
j=j+1
else:
break
- We perform few data cleaning operations such as replacing line breaks with a space and copy the data into .csv file which can be used for further analysis.
import copy
data = copy.deepcopy(data)
def remove_space(s):
return s.replace("\n"," ")
data['review'] = data['review'].apply(remove_space)
data.to_csv('amazon_reviews.csv', header=True, sep=',')
data = pd.read_csv('amazon_reviews.csv',index_col=[0])
data
- Since the goal of further analysis is to perform topic modeling, we will solely focus on the review text, and drop other metadata columns i.e. date and user name.
# Remove the columns
data = data.drop(columns=['date', 'username'], axis=1)
# Print out the data
data
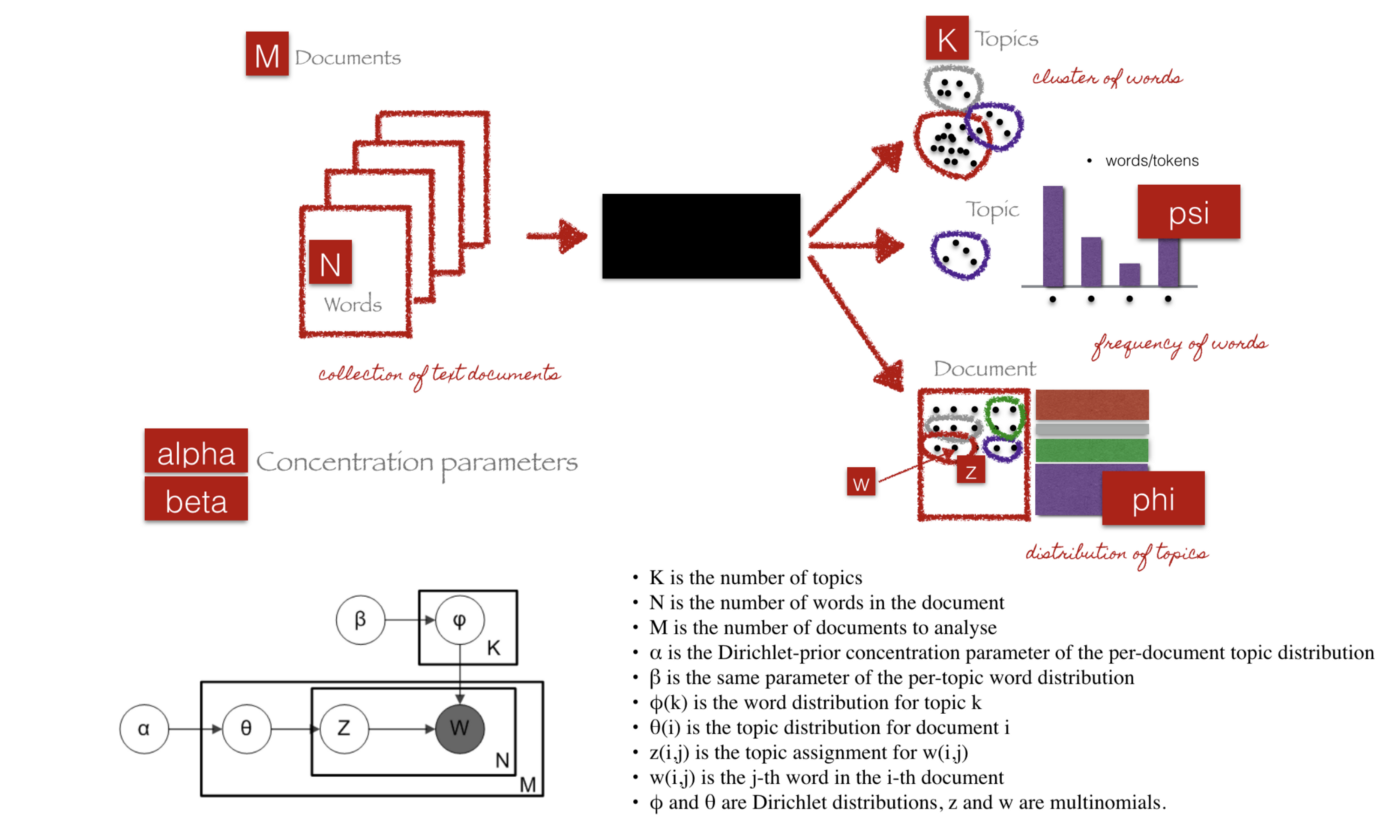
Topic modeling is a type of statistical modeling for discovering the abstract “topics” that occur in a collection of documents. Latent Dirichlet Allocation (LDA) is an example of topic model and is used to classify text in a document to a particular topic. LDA is a generative probabilistic model that assumes each topic is a mixture over an underlying set of words, and each document is a mixture of over a set of topic probabilities.
Illustration of LDA input/output workflow (Credit: http://chdoig.github.io/pytexas2015-topic-modeling/#/3/4)
We will preprocess the review data using gensim library. Few of the actions performed by preprocess_string as follows:
- Tokenization: Split the text into sentences and the sentences into words. Lowercase the words and remove punctuation.
- All stopwords are removed.
- Words are lemmatized: words in third person are changed to first person and verbs in past and future tenses are changed into present.
- Words are stemmed: words are reduced to their root form.
Please see below the output after pre-processing one of the reviews.
import gensim
from gensim.parsing.preprocessing import preprocess_string
# print unprocessed text
print(data.review[1])
# print processed text
print(preprocess_string(data.review[1]))
processed_data = data['review'].map(preprocess_string)
processed_data
Gensim requires that tokens be converted to a dictionary. In this instance a dictionary is a mapping between words and their integer IDs. We then create a Document-Term-Matrix where we use Bag-of-Words approach returning the vector of word and its frequency (number of occurences in the document) for each document.
# Importing Gensim
import gensim
from gensim import corpora
# Creating the term dictionary of our list of documents (corpus), where every unique term is assigned an index.
dictionary = corpora.Dictionary(processed_data)
# Converting list of documents (corpus) into Document Term Matrix using dictionary prepared above.
doc_term_matrix = [dictionary.doc2bow(doc) for doc in processed_data]
We will now run the LDA Model. The number of topics you give is largely a guess/arbitrary. The model assumes the document contains that many topics. However, finding the number of topics explaining the data is a optimisation problem and can be found by 'Coherence Model'.
Here, we have used number of topics = 3
#RUN THE MODEL
# Creating the object for LDA model using gensim library
Lda = gensim.models.ldamodel.LdaModel
# Running and Trainign LDA model on the document term matrix.
TOPIC_CNT= 3
ldamodel = Lda(doc_term_matrix, num_topics=TOPIC_CNT, id2word = dictionary, passes=50)
We can then see the weights of top 20 words in each topic, which can help us to explain the topic.
#Results
topics= ldamodel.print_topics(num_topics=TOPIC_CNT, num_words=20)
topics
We can identify the follow topics emerging out of reviews of Amazon iPhone 11 64GB:
- Topic #1: There seems to discussion of heat/ charging issue with the product.
- Topic #2: The discussion on iPhone's features such as camera, display, battery.
- Topic #3: iPhone being value for money and discussion on Amazon delivery service.
word_dict = {};
for i in range(TOPIC_CNT):
words = ldamodel.show_topic(i, topn = 20)
word_dict['Topic #' + '{:2d}'.format(i+1)] = [i[0] for i in words]
pd.DataFrame(word_dict)
The below code provide the % of topic a document is about. This helps to find the dominant topic in each review.
doc_to_topic = []
for i in range(len(doc_term_matrix)):
top_topics = ldamodel.get_document_topics(doc_term_matrix[i], minimum_probability=0.0)
topic_vec = [top_topics[j][1] for j in range(TOPIC_CNT)]
doc_to_topic.append(topic_vec)
#Dataframe of topic
document_topics = pd.DataFrame(doc_to_topic)
document_topics = document_topics.rename(columns=lambda x: x + 1)
document_topics.columns = document_topics.columns.astype(str)
document_topics = document_topics.rename(columns=lambda x: 'Topic #' + x)
#Dataframe of review and topics
data_new = pd.concat([data,document_topics],axis=1,join='inner')
data_new.head()
I hope this blog helps in understanding how powerful Topic Modeling is in understanding unstructured textual data. Feel free to play around with the code by opening in Colab or cloning the repo in github.
If you have any comments or suggestions please comment below or reach out to me at - Twitter or LinkedIn